KFold is a class in the model_selection module of sklearn package. The usage of KFold is simple:
kfold=KFold(n_splits,shuffle, random_state)
Now, a KFold object is ready. Notice that the data to be split does not appear in the construction parameters of KFold. You should use the split method of the KFold object to split data:
kfold.split(data)
data is typically an array. kfold will split the array into n_splits groups. What is the returned value of kfold.split? It is not a list of split groups(folds). It is a generator object. So it an be used in the for…in… statement. When applying the next function to the generator, you’ll get a tuple, the tuple has two elements, both of which are array. The first element is the indices(for the data array) of training data. The second element is the indices(for the data array) of the test data. You can use the fancy indexing to get the actual training data and test data from the original data array. The union of test data and training data is the original data. So, kfold.split is just used to split the original data into training set and test set, not n folds.
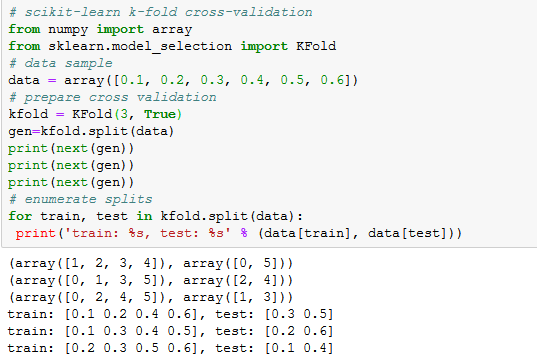
# scikit-learn k-fold cross-validation
from numpy import array
from sklearn.model_selection import KFold
# data sample
data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6])
# prepare cross validation
kfold = KFold(3, True, 1)
# enumerate splits
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train], data[test]))
The generator generates the test data indices by taking the indices of the data in each group in order, and generates the training data indices by taking the indices of remaining data keeping their order in the original data array.

From above, we can see the generator takes one fold as the test set from folds in order and take the elements in each fold also in order. The generator only produces n(the fold number) results. Each result is a training/test set combination.
The shuffle parameter of the constructor of KFold indicates whether to shuffle the original data array before splitting the shuffled array into groups. The generator takes the test data from the split groups sequentially, regardless whether the spit groups are formed from the original data array or shuffled array. But the generator returns the indices for the original data array, not the shuffled array.

From the running result above, we can tell the shuffled array is [0.2,0.3,0.1,0.5,0.4,0.6].
If you set the shuffle parameter to true, you may need to provide a value for the random_state parameter. The random_state parameter is used to initialize the random number generator(so called seed). The random number generator will generator a permutation for the shuffle. So different random_state will produce different shuffled array. Fixed random_state will produce the same shuffled array every time. If you do not provide a random_state, the seed changes every time you construct the KFold object so you’ll get different results every run you run the code. To get expected and fixed result, you’d better provide a fixed random_state value.

Tip admin with Cryptocurrency
Donate Bitcoin to admin

Donate Bitcoin Cash to admin

Donate Ethereum to admin

Donate Litecoin to admin
Donate Monero to admin
Donate ZCash to admin